SGD에서 배치 사이즈가 학습과 성능에 미치는 영향
“SGD(Stochastic gradient descent)에서 배치 사이즈(batch size)가 커지면 최적화 난이도와 일반화 성능은 어떻게 될까?”라는 질문에 대한 답을 찾기 위해 조사해 본 결과를 정리해보았다. 우선 SGD와 배치 사이즈의 의미부터 되짚어 보자.
-
Gradient descent: 딥러닝도 결국에는 로스 함수를 최소화하는 최적화 문제를 푸는 과정이라고 할 수 있고, 이 때 사용되는 가장 보편적인 방법이 ‘gradient descent’ 방법이다. ‘Gradient descent’는 최적화 시키고자 하는 함수를 파라미터에 대해서 미분하여, 기울기(gradient)를 구한 뒤 해당 기울기의 역방향으로, 즉 함수가 하락(descent)하는 방향으로 파라미터를 업데이트 하는 방법이다. 비유적으로 표현하면 산에서 골짜기를 찾기 위해 내리막 방향으로 이동하는 것으로 생각할 수 있다.
-
Batch gradient desent v.s. Stochastic gradient descent: ‘Gradient descent’에서 기울기를 계산할 때 , 모든 학습용 데이터를 이용하여 기울기를 계산한 뒤, 이를 파라미터 업데이트를 하는 경우를 일반적인 ‘(Batch) Gradient descent’라고 한다. 여기서 ‘batch’는 가지고 있는 모든 데이터를 한 회분(batch)의 업데이트에 이용한다는 의미로 이해할 수 있다.
그리고 모든 데이터가 아닌 일부 데이터를 이용해서 기울기를 구하여 파라미터를 업데이트 하는 것이 ‘Stochastic gradient descent (SGD)’ 방법이다. ‘Stochastic’이란 랜덤 정도의 의미로 해석할 수 있는데, 모든 데이터를 사용하지 않고 일부 데이터를 사용하기 때문에 어떤 데이터를 사용하느냐에 따라 업데이트에 무작위성이 개입한다는 의미로 이해할 수 있다.
-
(Mini-)Batch Size: 본래 SGD는 하나의 관측치(data point)를 이용해서 계산한 기울기를 이용해서 파라미터를 업데이트 하는 것인데, 일반적으로는 두 개 이상의 관측치들을 이용해서 기울기를 계산한다. 이때 한 번 업데이트에 사용하는 데이터를 미니 배치(mini-batch)라고 하는데 일반적으로 SGD에서 배치 사이즈(batch size)라고 하면 전체 학습 데이터의 크기가 아니라 미니 배치의 크기, 즉 미니 배치에 사용되는 관측치들의 수를 말하게 된다.
배치 사이즈에 따른 두 가지 변화: 최적화 난이도, 일반화 성능
배치 사이즈는 학습 시 정해야하는 하이퍼 파라미터로 이것에 따라 학습 양상과 결과가 달라질 수 있다. 어떤 경향성이 있을까? 아래와 같은 보다 상세한 두 가지 질문을 던져볼 수 있다.
1. 최적화 난이도: 배치 사이즈가 커지면 학습이 쉬워질까?
2. 일반화 성능: 배치 사이즈가 커지면 학습한 모델이 새로운 데이터에서도 잘 작동할까?
최적화 난이도
학습 과정에서 최적화가 잘 수행되는지는 학습 시 로스 함수의 수렴 속도 혹은 학습용 데이터셋에 대한 성능이나 로스를 보고 판단할 수 있다. 수렴이 빠르게 되고, 학습용 데이터셋에 대한 성능이 높거나 로스가 낮은 경우 학습 또는 최적화가 비교적 용이하게 되는 바람직한 경우라고 할 수 있다.
일반적으로 배치 사이즈가 커질수록 장단이 있기 때문에 최적화 난이도가 단정적으로 쉬워지거나 어려워진다고 말하기 어렵다.
배치 사이즈가 큰 경우 기울기를 계산하기 위해 더 많은 데이터를 사용하게 되므로 우리가 최적화 시켜야하는 전체 학습용 데이터를 사용한 해공간의 기울기 값과 유사한 기울기를 사용하므로 최적화가 더 수월해질 수 있다. 하지만 실제 최적화 시켜야할 문제공간이 평평한 경우에는 실제와 유사하게 근사된 기울기의 절대값이 작아 수렴 속도가 매우 느려질 수 있고, 극단적인 경우에는 극소점(local minima) 혹은 안장점(saddle point)에 빠져서 로스가 줄어들지 않을 수도 있다.
반면에 배치 사이즈가 작은 경우 상대적으로 부정확한 기울기를 사용한다는 단점이 있지만, 한번의 업데이트에 적은 계산 비용이 들어가 한번 업데이트 할 동안 여러번의 업데이트를 수행할 수 있고, 기울기의 부정확한 면이 랜덤성으로 작용해 실제 기울기가 낮은 구간이나 극소점, 안장점에서 쉽게 벗어날 가능성이 있다는 장점이 있다.
일반화 성능
일반화 성능은 학습이 끝난 뒤, 학습에 사용하지 않은 데이터 셋에 대한 모델의 성능을 통해 살펴볼 수 있다.
Keskar et al(2017)에 따르면 배치 사이즈가 커질수록 일반화 성능이 떨어지는 현상이 관측되었다. 이를 Keskar et al(2017)은 배치 사이즈가 커질수록 ‘sharp minimizer’로 수렴하기 때문이라고 주장하였다. ‘sharp minimizer’는 아래 그림에서 ‘sharp minimum’과 같이 로스 함수의 굴곡이 커서 학습과 테스트 시 조금만 어긋나도 성능이 급격하게 변하는 지점의 개념으로 이해할 수 있다.
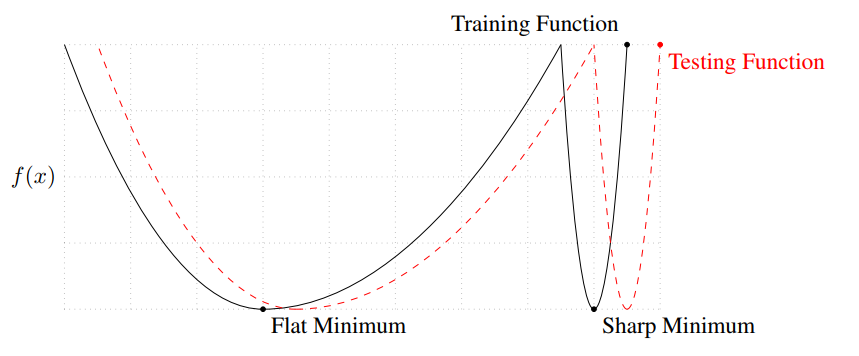 ‘sharp minimizer’의 개념도. x축은 파라미터 y축은 로스 함수의 값을 의미한다. (출처: Keskar et al(2017))
‘sharp minimizer’의 개념도. x축은 파라미터 y축은 로스 함수의 값을 의미한다. (출처: Keskar et al(2017))
반면에 Goyal et al(2017)은 자신들의 방법대로 학습하면 배치 사이즈를 8K까지 늘려도 일반화 성능의 하락이 관측되지 않았고, 더 나아가 You et al(2017)은 자신들의 방법을 이용하면 ‘Resnet-50’을 이용했을 때 32K까지 배치 사이즈를 늘려서 학습해도 정확도가 떨어지지 않는다고 주장하였다.
배치 사이즈를 키우는 이유?
지금까지의 내용을 종합하면 배치 사이즈를 키우면 학습이 좀 더 쉬워진다고 단정지어 말하기고 어렵고, 일반화 성능은 오히려 하락하기도 한다. 그렇다면 원래 SGD처럼 배치 사이즈를 1로 하는 것이 가장 좋을 것 같은데, 실전에서는 배치 사이즈를 메모리에 올라갈 수 있는 한 최대로 설정하는 경우가 많다. 그 이유는 무엇일까?
이유는 계산 효율에 있다. 결과가 크게 다르지 않다고 하면, 벡터화 된 계산에서는 100개의 관측치를 이용해서 1번 업데이트 하는 것이 1개씩 관측치를 이용해서 100번 업데이트하는 것보다 더 적은 계산 비용이 든다. 또한, 병렬처리 시 하나의 미니 배치 안에서 여러 관측치를 이용해서 기울기를 계산하는 과정에서는 골치 아픈 동기화 작업이 필요 없고, 계산한 기울기를 이용해서 파라미터를 업데이트 과정에서는 동기화 작업이 필요하기 때문에 큰 배치 사이즈로 더 적게 업데이트를 한다고 하면, 작은 배치 사이즈로 업데이트를 많이 하는 것보다 병렬화하기 쉬워 계산 비용을 절약할 수 있기 때문이다.
더불어 앞에서 살펴본 논문들(Keskar et al(2017), Goyal et al(2017), You et al(2017))에서 일반화 성능이 떨어지는 것이 관측된 경우는 여러 대의 연산장치를 이용해서 일반적인 배치사이즈인 32-512를 넘어서서 학습하는 경우이다. 여러 대의 연산장치를 이용하지 않는 경우에는 배치 사이즈를 위 연구들처럼 일반화 성능이 떨어지는 것을 관측할 수 있을 때까지 키울 수도 없다. 따라서 많은 경우에서 연산의 효율성을 위해 배치 사이즈를 메모리에 올라갈 수 있는 한 최대한 크게 설정해도 일반화 성능이 떨어질 걱정을 하지 않아도 되는 것이다.
물론 학습이 잘 되지 않거나 학습한 모델의 성능이 낮은 경우에는 배치 사이즈도 원론적으로는 하이퍼 파라미터이므로 조정이 필요할 것이다.
Reference
- https://stats.stackexchange.com/questions/164876/tradeoff-batch-size-vs-number-of-iterations-to-train-a-neural-network
- https://www.quora.com/Intuitively-how-does-mini-batch-size-affect-the-performance-of-stochastic-gradient-descent
- Keskar et al, “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima”, 2017
- Goyal et al, “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”, 2017
- You et al, “Large Batch Training of Convolutional Networks”, 2017