캐글(Kaggle) 대회(Competition) 도전기: Statoil/C-Core Iceberg Classifier Challenge
데이터 분석을 하는 사람들의 SNS라고도 불리는 캐글(Kaggle)에서는 데이터를 기반으로 더 좋은 예측 모델을 만드는 대회(competition)들이 열리는데, 그중 하나에 한 번 참여해보았다. 대회에 직접 참여했던 사람들이 아니라면 도움 혹은 공감이 안 되겠지만 스스로 대회를 마무리 짓는 차원에서 글로 정리해보았다.
Statoil/C-Core Iceberg Classifier Challenge
“Statoil/C-Core Iceberg Classifier Challenge”는 위성으로 찍은 사진이 빙하인지 선박인지 구분해 내는 모델을 만드는 것을 목적으로 하는 대회이다. C-Core라는 회사는 위성으로부터 받은 정보를 이용해서 컴퓨터 비전 기반으로 환경을 모니터링 하는 시스템을 만들어왔는데, 에너지 회사인 Statoil사가 C-core의 시스템을 이용해서 작업시 위협이 되는 빙하를 조기에 발견하고 싶었고, 따라서 본 대회를 두 회사가 같이 주최하게 되었다. 이외의 자세한 설명은 직접 대회 페이지에 들어가면 확인해 볼 수 있다.
고민 및 시도
대부분 참가자와 같이 딥러닝/머신러닝을 이용해서 접근하였고, 좋은 성적을 거두기 위해 여러 가지 고민 및 시도를 해보았는데, 그 내용을 아래와 같은 네 가지 항목으로 정리해보았다.
1. 문제 정의
- 본 대회의 문제는 주어진 이미지가 빙하인지 선박인지를 분류하는 이진 분류 문제이다. 문제 정의가 명확하여 특별히 다른 고민을 하지는 않았지만, 문제 정의의 중요성을 고려하여 확인차 하나의 항목으로 적어보았다.
- 대회에서 모델의 성능을 평가하는 척도로는 로그로스(log loss)를 사용한다.
2. 데이터
- 이미지 예시
- 본 대회의 데이터는 영상 정보로 위성 레이더 값을 사용하기 때문에 이미지에 해당하는 데이터가 기존 RGB값처럼 3채널이 아니라 ‘HH(transmit/receive horizontally)’와 ‘HV(transmit horizontally and receive vertically)’라 불리는 2채널로 이루어져 있고, 보편적인 8비트 이미지(0~255 사이의 정숫값을 가짐)가 아니라 값이 소수점을 가지는 값으로 주어진다.
- 주어진 대로 데이터를 이용할 것인가, 아니면 영상 데이터를 3채널로 변형하고 데이터 형식도 8비트로 만들어서 보편적인 데이터 형태로 이용할 것인가 하는 고민이 있었는데, 결과적으로는 주어진 대로 이용하였다. 고민을 해결하기 위해 단순히 첫 번째 채널의 값과 두 번째 채널의 값을 더해서 세 번째 채널로 만들어서 학습 및 검증을 했을 때 성능 향상이 없었고, 8비트 이미지를 만들기 위해 0~255사이로 정규화하여 정수값으로 만들었을 때는 소수점의 정보 손실 때문인지 성능 하락이 있었기 때문이다.
- 본 대회에서는 이미지에 해당하는 데이터와 더불어 입사각(incidence angle)이라는 수치가 이미지마다 주어진다. 입사각의 의미를 정확히 이해하지는 못했지만, 데이터 탐색을 통해 입사각이 똑같은 데이터가 존재하고, 입사각이 같은 데이터는 대부분 같은 범주에 속한다는 사실을 발견하였다. 따라서 이와 같은 사실을 이용해서 데이터 클렌징과 모델 선택을 위한 검증 환경을 설계하였다.
- 데이터 클렌징: 같은 입사각을 가지는 군집은 모두 같은 범주에 속한다는 가정하에, 하나의 군집 안에서 극소수 데이터들이 대다수의 범주와 다른경우, 소수의 범주를 대다수 범주로 수정하였고, 극소수가 아니여서 해당 군집의 범주를 예상하기 어려운 경우에는 해당 군집을 학습데이터에서 제외했다.
- 검증 환경: 같은 입사각을 가지는 데이터는 유사성이 높은 데이터라고 생각하여, 같은 입사각을 가지는 데이터를 학습(training)과 검증(validation)에 둘 다 사용하게 된다면, ‘답보고 답 맞추기’ 식의 검증이 될 수도 있을 것으로 생각하였다. 따라서 학습용 데이터와 검증용 데이터를 나눌 때 같은 입사각을 가지는 군집은 학습용 혹은 검증용 데이터 중 한 곳에만 속하도록 나누었다.
- 이 외에 입사각을 빙하/선박 분류에 직접 사용할 방법을 고민했었는데, 하나의 피처로 쓰는 단순한 방법 이외의 좋은 아이디어는 떠올리지 못하였다. (결과적으로 입사각을 어떻게 이용했느냐가 대회에서 좋은 성적을 거두는데 핵심 요소였다.)
- 약 1600개의 학습용 데이터가 있는데 학습 시 데이터 증강(data augmentation)하기 위해 상하반전(vertical flip), 좌우반전(horizontal flip), 그리고 4개의 각 모서리와 중점을 중심으로 이미지를 잘라내는 방법(5 cropping)을 이용했고, 학습뿐만 아니라 모델의 성능 검증 혹은 결과물을 제출하기 위해 결과를 낼 때도 5 cropping을 적용하여 잘라낸 5개의 이미지의 예측 평균값을 해당 이미지의 예측값으로 사용하였다. 해당방법 처럼 평가를 할 때도 데이터 증강을 한 뒤 그 결과를 종합하는 것을 TTA(Test-Time Augmentation)라고 하는데, 이를 통해 모델의 평가시간은 길어졌지만, 과적합 문제를 완화하고 검증 단계에서의 성능을 좀 더 안정적으로 만들어 주는 데 많은 도움을 얻을 수 있었다.
- 선박 혹은 빙하로 추정되는 물체가 가운데에 포착된 데이터가 많은데, 중요하지 않은 정보인 외곽 부분을 잘라내면 더 본질에 집중하는 모델을 만들 수 있을 것으로 생각하여, 크기 (75x75x2)의 이미지를 (60x60x2)의 크기가 되도록 가운데 부분만을 잘라내어 학습 및 검증해보았는데 성능이 오히려 하락하였다.




3. 모델
- 유명 구조의 모델(VGG, ResNet, DenseNet 등)과 전이 학습(Transfer Learning) 방식은 사용하지 않았다. 일반적으로 성능이 좋다고 알려진 구조의 모델 중 이미지넷(ImageNet) 등을 통해 미리 학습된 모델(pre-trained model)을 가져와서 재학습하는 방식이 성능이 좋다고 알려져 있는데, 내가 시도해본 미리 학습된 모델들은 초기에 학습 로스가 빨리 줄어들지만, 검증 로스가 줄어들지 않는 과적합 문제가 심각하였고, 본 대회의 데이터가 미리 학습할 때 사용한 이미지와는 성격이 많이 다르다고 생각하여 새로운 모델을 바닥부터 학습하는 방식을 사용해보기로 하였다.
- 기본 구조는 컨볼루션(Convolution)-활성화(Activation)-풀링(Pooling)을 기반으로 컨볼루션 레이어 혹은 필터의 수를 변경해보거나 활성화 혹은 풀링 방법을 바꿔보거나 레즈넷(ResNet)에서 착안해서 스킵 커넥션(skip connection)을 추가해 보기도 하였고, 가장 심한 문제였던 과적합을 피하고자 배치노말리제이션(batch normalization)과 드랍아웃(drop out)을 모두 사용해 보았다.
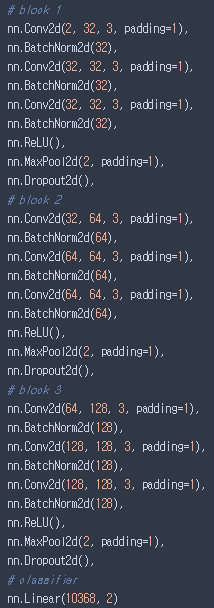
- 최종으로 사용하였던 모델 구조는 아래와 같았다. 그리고 성능은 공개 순위에서 log loss 0.14 정도를 달성하였다.
-
파이토치(PyTorch) 프레임워크로 구성한 모델 “StatoilNet” 구조
-
4. 기타: 앙상블(ensemble), 세미수퍼바이즈드(semi-supervised)
- 캐글 대회에서는 단일 모델로 경쟁력을 갖추기 어렵고, 여러 모델의 결과를 종합하는 앙상블이 필수다. 앙상블을 하기 위해 위에서 구성한 모델을 같이 사용하되 데이터를 교차 검증(cross-validation)방식으로 10개의 학습-검증 데이터셋 조합을 만들어서 학습한 10개의 모델을 앙상블 하였다. 또한, 약간의 편법의 성격이 있지만, 대회 게시판과 같은 디스커션 탭에 올라오는 글 중에 다른 사람의 테스트셋에 대한 예측값을 활용해서 내 앙상블 모델을 포함한 총 6개의 모델을 이차적으로 앙상블했다. 결과론적으로는 앙상블을 통해 로그로스(log loss) 0.14대에서 0.12대로 진입해서 가장 성능을 많이 올릴 수 있었다.
- 테스트 데이터에 대한 레이블은 주어지지 않지만, 이미지 값을 이용할 수 있기 때문에 평소에 관심이 있었던 세미수퍼바이즈드(semi-supervised) 방법으로 셀프앙상블(self-ensemble)인 Laine & Alia(2017)의 방법론 야심 차게 도입해 보았으나, 기존의 로스 이외에 추가된 셀프 앙상블을 위한 로스의 최적화 과정이 분류하는 데 도움을 주는 게 아니라 더 악영향을 주었는지, 성능이 오히려 더 하락하였다.
대회가 끝나고
공개 순위 과적합
캐글 대회에서는 자신의 모델이 잘 작동하는지, 다른 사람의 성능에 비해 내 성능은 어떤지 확인하기 위해 일부(본 대회에서는 전체 테스트 셋의 20%) 테스트 셋에 대한 성적을 대회 기간에 공개한다. 하지만 모든 테스트 셋에 대한 성적을 공개하면 테스트 셋에 대한 피팅을 유발하여 일반화 성능이 떨어지는 모델이 높은 순위를 차지할 수 있기 때문에, 대회가 끝날 때까지 나머지 테스트 셋에 대해서는 성적을 공개하지 않고, 대회가 끝나면 남겨두었던 테스트 셋에 대한 성적을 최종 성적으로 사용한다. 전자의 성적 순위을 공개 순위(public leader board), 그리고 후자를 비공개 순위(private leader baord)라고 한다.
대회가 끝나고 비공개 순위가 발표되었을 때 일부 공개 순위의 상위권에 있던 사람들의 순위가 매우 극단적으로 떨어지는 현상이 발견되었다. 심하게는 앞에서 10위권이었는데 뒤에서 200등 정도로 떨어지는 사람도 있었는데 이러한 사람들은 대부분 공개 순위를 척도로 앙상블 방법을 달리하거나 최종 예측치에 대해 임시방편적인 후처리를 다르게 하면서 공개 순위에서의 성적을 올렸던 것으로 추측된다. 즉 공개 순위에 대해서 과적합 되어 비공개 순위에서는 일반화 성능이 떨어진 것이다. 이러한 안타까운 일이 발생하지 않으려면 공개 순위에서의 성적이 아니라 교차 검증 등을 이용해서 통계적으로 유의미하게 로컬에서 나의 성능을 검증할 수 있는 환경을 구성하고 이를 이용해서 모델을 선택해야 할 것이다.
우승자의 방법
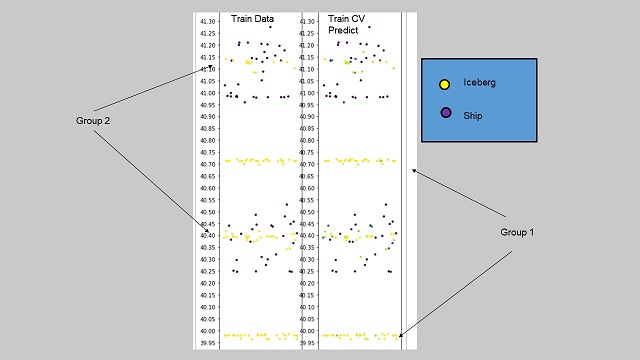
1등을 한 참가자(David&Weimin)의 방법론은 CNN 과 앙상블을 사용했다는 것은 본인을 비롯한 다른 사람들과 비슷하지만, 하나 달랐던 점이 입사각을 잘 활용한 것이다. 입사각을 빙하인지 선박인지 해당하는 변수(레이블)와 함께 그래프로 표현해보면 눈으로 보기에 두 그룹이 존재한다. 하나의 그룹은 대부분이 빙하이고, 하나의 그룹은 빙하와 배가 섞여있었는데 해당 정보를 활용해서 모델을 세웠다. 따라서 입사각과 레이블을 관련지어서 자세히 살펴보지 않았다는 후회가 들었고, 철저한 데이터 탐색에 대한 중요성을 다시 한번 절감할 수 있었다.
- 입사각-레이블의 관계 시각화 (출처: 대회 게시판 내 David의 글)
무엇을 얻었나
이번 대회에서 나의 성적은 상의 7% 정도에 해당하는 226위 였고, 상위 10%까지 인정해주는 캐글내에서의 브론즈 배지를 받아 소소한 성취감을 얻을 수 있었다. 하지만 성적도 성적이지만 대회에 도전하면서 다양한 사람들의 방법론이나 의견을 보고, 어떻게 하면 성능이 좋아질까 고민해보면서 배움을 얻을 수 있었던 것이 나에게는 가장 큰 성과였다. 물론 3위안에 들어서 상금을 얻었다면 더 좋았겠지만, 이는 다음 기회로 미루어 놓아야겠다.
부록: 코드
대회를 진행하면서 사용했던 코드들 중에 몇가지를 모아서 아래 링크에 올려 놓았다.
링크: https://github.com/hongdoki/statoil-iceberg-classifier-challenge