BMVC 2018 리뷰: 대칭성에 관한 키노트와 5편의 논문
BMVC(British Machine Vision Conference)는 영국에서 열리는 머신 비전 학회이다. 1985년부터 시작하여 올해로 28번째를 맞이하였고, 매해 영국 내 다른 장소에서 열리는데 이번에는 뉴캐슬어폰타인이라는 영국의 북부에 있는 도시에서 열렸다.
올해 제출된 논문 수는 대부분의 컴퓨터 비전학회들과 같이 증가세를 보여서 862편이며, 그중 약 30%에 해당하는 255편이 채택되었다. 가장 큰 컴퓨터 비전 학회인 CVPR 2018은 3300편 중 979편이 채택되었고, BMVC가 끝나고 2일 뒤에 열린 ECCV 2018에는 2439편 중 776편이 채택되었던 것을 보면 메이저 학회들과 비교해 봤을 때 채택된 비율은 비슷하지만, 규모는 상대적으로 작은 학회이다. 논문이 채택된 지역의 분포를 보면 영국에서 열리는 학회이니만큼 영국도 많지만, 아시아가 가장 많은 부분을 차지하는 것을 확인해볼 수 있다.
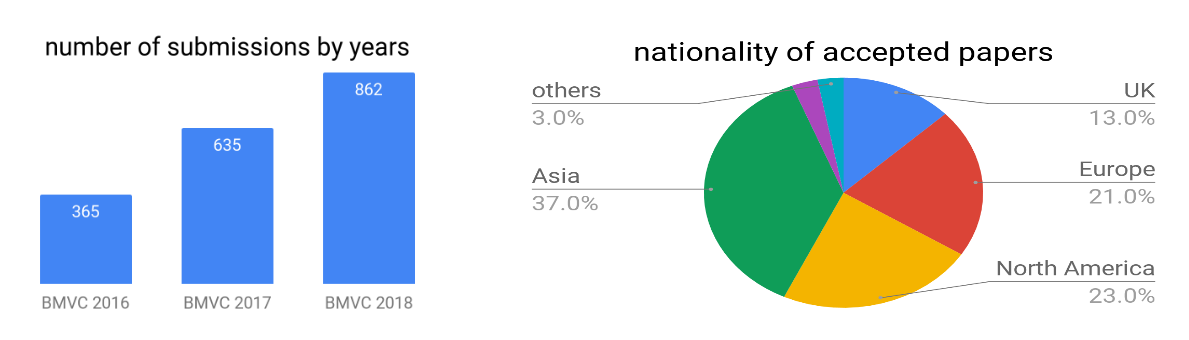 2016 ~ 2018에 BMVC로 제출된 논문 수, BMVC 2018에서 채택된 논문의 지역 분포
2016 ~ 2018에 BMVC로 제출된 논문 수, BMVC 2018에서 채택된 논문의 지역 분포
BMVC 2018는 견학의 목적으로 다녀왔는데, 다녀온 뒤 흥미로웠던 키노트 1개와 논문 5개를 시간이 지났지만 글로 남기고자 한다.
키노트: 휴먼 비전과 컴퓨터 비전에서 ‘대칭성’의 역할
우선 키노트는 Sven J. Dickinson이라는 연구자의 ‘대칭성(Symmetry)’에 대한 연구 내용이었다. 우선, 해당 연구자의 연구는 어떤 이미지가 어떤 장면에 해당하는지, 예를 들어 어떤 사진이 바다를 찍은 사진인지 산을 찍은 사진인지를 분류하는 장면 분류(scene classification) 작업을 기반으로 진행되었다. 처음에 그가 모티브를 얻은 것은 Walther and Shen의 2014년 연구이다. 해당 연구에서는 사람은 이미지의 윤곽선만으로도 장면 분류를 잘한다는 사실에서 시작하여, 외곽선의 어떤 특성이 사람의 장면 분류 성능에 도움을 주는지 실험을 해보았다. 해당 실험은 외곽선의 방향, 길이, 곡률 같은 ‘1차원 적인 특성’과 외곽선의 교차 유형, 교차 각도와 같은 ‘관계적인 특성’에 기반하여 외곽선의 색을 달리한 이미지들을 이용해서 어떤 특성이 장면 분류에 중요한지 실험하여, 외곽선들의 ‘관계적인 특성’이 ‘1차원 적인 특성’보다 더 중요하다는 결과를 얻었다.
 외곽선의 특성에 따라 색을 달리한 이미지, Walther and Shen (2014)
외곽선의 특성에 따라 색을 달리한 이미지, Walther and Shen (2014)
해당 연구를 보고 Sven은 외곽선에서 선들의 관계를 좀 더 탐구해보고자 두 가지 실험을 하였는데, 첫 번째 실험은 외곽선의 가운데 부분(middle line)과 선들이 교차하는 부분(junction line) 중에 어느 부분이 장면 분류에 더 중요한 요인인지를 살펴보는 실험이다. 각각을 제거한 외곽선 이미지들을 이용하여, 사람이 장면을 인식하기에는 외곽선의 가운데 부분을 제거한 이미지들이 더 어렵다는 결론을 끌어냈다. 아래는 가운데 부분과 교차하는 부분을 각각 제거한 이미지들이다.
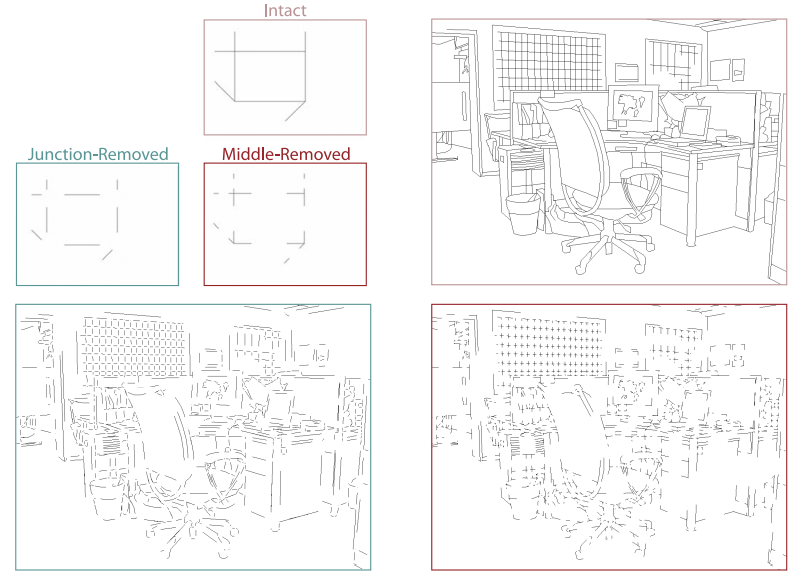 오른쪽 위가 원본 외곽선 이미지, 왼쪽 아래가 교차하는 부분을 제거한 외곽선 이미지, 오른쪽 아래가 가운데 부분을 제거한 외곽선 이미지, Wilter at el. (2018)
오른쪽 위가 원본 외곽선 이미지, 왼쪽 아래가 교차하는 부분을 제거한 외곽선 이미지, 오른쪽 아래가 가운데 부분을 제거한 외곽선 이미지, Wilter at el. (2018)
그렇다면 왜 가운데 부분을 제거하면 사람이 장면을 분류하기에 어려워지는 걸까? 연결 매끄럽지 않지만, Sven은 가운데 부분을 제거하면 이미지의 대칭성이 깨져서 인식하기 힘들어졌을 것이라는 가정을 세운다. 대칭성은 자연계 이미지에 어디에나 편재하고 있는 특성으로 새의 두 날개에서 볼 수 있는 거울 대칭성(mirror symmetry), 꽃잎에서 볼 수 있는 회전 대칭성(rotational symmetry) 등이 그 예시이고, 전체적인 대칭성이 아니라도 국지적인 대칭성은 사람의 몸과 같은 곳에서도 쉽게 발견할 수 있다고 한다. 그리하여 Sven은 위와 같은 가설을 기반으로 대칭성에 관한 두 번째 실험을 진행하였다.
Sven의 두 번째 실험은 첫 번째 실험과 유사하게 대칭성이 높은 부분과 대칭성이 낮은 부분 중에 어느 부분이 장면 분류에 더 중요한 부분인지를 비교하는 실험이었다. 즉, 윤곽선의 대칭성이 높은 부분과 낮은 부분을 각각 제거하여 사람에게 제시한 뒤 장면 분류의 성능을 비교하는데, 이를 위해서 MAT(Medial Axis Transformation)이라는 1967년에 발표된 방법을 이용하여 윤곽선의 해당 부분이 얼마나 대칭적인지를 알 수 있는 척도로 사용하였다. 실험 결과는 예상할 수 있듯이 대칭성이 높은 외곽선을 남겼을 때 사람이 장면 분류를 더 잘 해내는 결과를 보였다. 즉 사람이 어떤 이미지를 보고 산인지 바다인지 예측하기 위해서는 대칭성이 높은 외곽선이 중요하다는 것이다.
 첫 번째 열이 원본 외곽선 이미지, 두 번째 열이 대칭성이 높은 부분만 남긴 이미지(symmetric), 세 번째 열이 대칭성이 낮은 부분만 남긴 이미지(asymmetrc), Wilder et al. 2 (2018)
첫 번째 열이 원본 외곽선 이미지, 두 번째 열이 대칭성이 높은 부분만 남긴 이미지(symmetric), 세 번째 열이 대칭성이 낮은 부분만 남긴 이미지(asymmetrc), Wilder et al. 2 (2018)
여기까지가 사람의 시각적 작용과 연관된 휴먼 비전에서의 대칭성의 역할을 다룬 해당 키노트의 전반 내용이고, 후반은 사람이 아닌 컴퓨터 비전에서의 대칭성의 역할을 살펴볼 수 있는 내용이다. AMAT(Appearance Media Axis Transformation)라는 걸 고안하여 이미지를 변환하고 재건하는 내용인데 전반부 내용보다 이해도 및 흥미도가 낮아 자세한 내용은 생략하겠다.
해당 키노트가 흥미로웠던 점은 우선 첫 번째로 대칭성이라는 성질에 대해 이미지 인식에서 고려했다는 사실이다. 평소 대칭성은 어디에서나 발견할 수 있지만 이를 연구 대상으로 삼았다는 게 신선하게 다가왔다. 또한 휴먼 비전과 컴퓨터 비전의 연구를 연결 지어서 연구한다는 점이 흥미로웠다. 물론 아직은 휴먼 비전에서 대칭성이 중요하다는 점을 본인이 관심 있어 하는 딥러닝 분야로 활용할 수 있는 방안은 아직 연구 중이라고 하지만 추후 서로의 분야에 새로운 시각을 제시해서 두 분야 모두 발전을 이룰 수 있을 것 같다는 생각이 들었다.
아쉬운 점도 있다. 우선 앞서 말했듯이 대칭성의 활용 방안이 아직은 부족하다는 점이 있고, 장면 인식 문제에만 한정되어서 연구되고 있다는 사실이 다른 시각적인 작업에 적용되기에 범용성이 떨어질 수 있겠다는 생각이 들었다. 대칭성에 대해서 열심히 연구해서 컴퓨터가 시각적인 작업을 하는 데 도움이 되는 특성을 찾아서 활용한다고 해도, 결국 머신 러닝 방식으로 학습한 하나의 특성보다 활용도가 떨어지지 않을까 하는 우려도 들었다. 위의 키노트 내용은 BMVC 2018의 모든 세션이 업로드되어있는 BMVC 2018 유튜브 채널의 영상에서 찾아볼 수 있고, 전반부 내용만 본다면 Sven이 본인이 교수로 있는 대학에서 강의한 영상에서도 찾아볼 수 있다. 전자는 소리가 작아 알아듣기 조금 어려우므로 전반부의 내용만 본다면 후자의 링크에서 보는 것을 추천한다.
논문 1: Vithursan and Graham, Self-Paced Learning with Adapative Deep Visual Embeddings
BMVC 2018에 참관하면서 살펴본 논문 중에서는 흥미로웠던 5개의 논문을 소개해보겠다. 첫 번째 논문은 Vithursan and Graham의 “Self-Paced Learning with Adaptive Deep Visual Embeddings”라는 제목의 논문으로, 딥러닝에서 SGD를 이용해 학습할 때의 배치 샘플링에 관련된 연구이다. 배치를 구성하는 것을 데이터 스케줄링이라고도 하는데, 데이터 스케줄링 시 일반적으로 사용되는 균등(uniform) 샘플링은 최적이 아닐 수 있다고 하면서 논문을 시작한다.
물론 이런 문제의식을 느낀 연구는 이미 많이 있으며, 그 중 논문에서 언급된 것은 샘플별 최적화 난이도를 고려하는 연구와 샘플들의 다양성을 고려하는 연구이다. 조금 더 구체적으로는 난이도를 고려한 연구 중에서는 쉬운 샘플에서 어려운 샘플로 순서로 스케줄링해주는 ‘커리큘럼 학습’(Curriculum Learning) 혹은 커리큘럼을 모델의 학습 양상에 맞게 동적으로 구성해주는 ‘자가 진도 학습’(Self-paced learning) 연구 분야가 있고, 자가 진도 학습 시 구성된 배치의 다양성을 고려하는 연구로 ‘다양성을 고려한 자가 진도학습’(Self-Paced Learning with Diversity, SPLD)가 있다. 해당 논문도 SPLD 방식으로 난이도는 학습 로스로 판단하고, 다양성은 거리 학습(metric learning)을 기반으로 고려하여 처음부터 끝까지 유기적으로 학습하는 프레임 워크를 제안한다. 특히, 거리 학습 방법론 중에 마그넷 로스(Magnet Loss)를 사용하여 좋은 성능을 보였다.
많은 경우 큰 고민 없이 사용하는 배치 샘플링 방법에도 샘플별 난이도와 다양성을 고려해서 차이를 주면 성능이 좋아질 수 있다는 점이 가장 흥미로웠다. 하지만 해당 방법론처럼 상황에 맞게 조정하는 방법들(예를 들면 Adam 최적화 방법론)을 이용한 모델은 오히려 과적합 위험이 더 커서, 일반화 성능이 떨어질 수 있지 않을까 하는 우려가 들었다. 또한 해당 방법론의 계산 비용이 기존의 작업을 위한 학습과 더불어 거리 학습에 필요한 비용도 추가로 소요된다는 단점이 있다. 물론 논문에서는 두 작업을 병렬적으로 처리할 수 있고 그렇게 하면 해당 비용을 완화할 수 있다고 한다.
논문 2: Petsiuk et al, RISE: Randomized Input Sampling for Explanation of Black-box Models
두 번째 논문은 Petsiuk et al.의 “RISE: Randomized Input Sampling for Explanation of Black-box Models”라는 딥러닝 모델의 예측 결과에 대한 시각적 설명에 관한 논문이다. 좀 더 구체적으로는 클래스별로 이미지에 어떤 부분이 해당 클래스로 예측하는데 주효하는지를 나타내는 이미지와 똑같은 크기의 하나의 맵을 만드는 방법을 제안했다. 해당 맵을 살리언시 맵(saliency map)이라고 하였는데, 아이디어는 단순하다. 입력 이미지에 여러 번 랜덤하게 특정 부분을 가리는 마스크를 씌워서 예측하여 나온 클래스별 점수를 다시 가중치로 해당 마스크들을 합산한 결과물을 이용하는 것이다. 기존에 사각형 패치를 슬라이딩 윈도우 방식으로 이동해가면서 비슷한 방식으로 모델을 시각화하는 방법론이 있었는데, 해당 논문은 그 작업을 사각형 패치가 아니라 무작위에 의한 형태의 만든 마스크를 이용한다는 것이 핵심이었다.
해당 방법의 장점으로는 기존의 모델 시각화를 위한 다른 방법론들에 비해 일단 성능이 뛰어난 것에 더하여, 입력에 마스크만 씌워주고 출력값을 확인하면 되므로 모델의 내부구조에 접근하거나 알고 있을 필요 없이 사용할 수 있다는 점을 부각하였다. 하지만 개인적으로는 랜덤효과를 이용하기 위해 여러 번 (예를 들면 1000번) 반복 작업을 수행해야 하므로 살리언시 맵을 얻기 위한 시간 및 계산적 비용이 많이 든다는 점이 장점을 상쇄할만한 단점이 될 것 같다는 생각이 들었다.
위 논문에서 또 하나 재미있었던 점은 즉 딥러닝의 해석 가능성(explainablity) 정도를 정량화할 수 있는 척도를 제시했다는 점이다. 기존에 살리언시 맵은 정량적으로 평가하는 척도가 없어서, 맵과 이미지를 보면서 정성적으로 평가할 수밖에 없었다. Petsiuk et al.은 해당 척도로 AUC(Area Under Curve)기반의 삭제(deletion)와 삽입(insertion)과 관련된 두 가지 척도를 제시하는데, 우선 삭제와 관련된 AUC를 계산하기 위해 살리언시 맵의 각 픽셀별 점수가 높은 순서대로 픽셀들을 점점 더 많이 지워가면서 해당 클래스의 확률을 그래프로 나타낸다. 그러면 아래 그림의 ‘삭제 곡선’처럼 점점 작아지는 곡선이 나타나는데 만약 해당 살리언시 맵이 해당 클래스로 판단하게 한 부분을 정확히 표현했다고 하면, 해당 곡선이 가파르게 낮아질 것이고, 그렇지 않다고 하면 완만하게 낮아질 것이다. 따라서 삭제와 관련 AUC는 낮을수록 해당 살리언시 맵의 품질이 좋다는 것을 가르킨다고 할 수 있다. 삽입과 관련된 AUC는 살리언시 점수가 높은 순서대로 반대로 아무것도 없는 이미지에 해당 픽셀 영역을 추가시켜줬을 때 예측 확률을 그린 그래프의 AUC를 구하는 것으로 이는 높을수록 좋은 척도라고 할 수 있다.
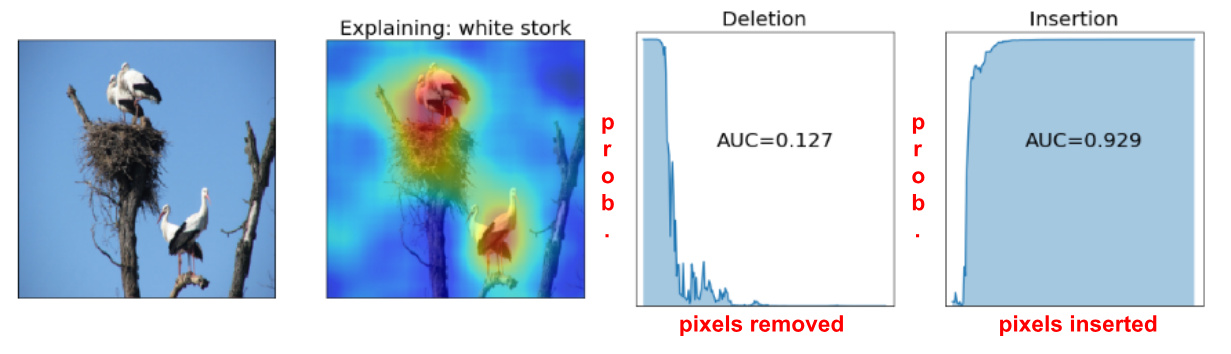 순서대로 원본 이미지, 원본 이미지에 살리언시 맵을 덧씌운 이미지, ‘삭제 곡선’(살리언시 점수가 높은 순서대로 픽셀을 지웠을 때의 해당 클래스의 예측 확률), ‘삽입 곡선’(살리언시 점수가 높은 순서대로 픽셀을 삽입했을 때의 해당 클래스의 예측 확률)
순서대로 원본 이미지, 원본 이미지에 살리언시 맵을 덧씌운 이미지, ‘삭제 곡선’(살리언시 점수가 높은 순서대로 픽셀을 지웠을 때의 해당 클래스의 예측 확률), ‘삽입 곡선’(살리언시 점수가 높은 순서대로 픽셀을 삽입했을 때의 해당 클래스의 예측 확률)
논문 3: Park et al., BAM: BottleNeck Attention Module
나머지 논문들은 네트워크 아키텍처에 관한 논문들이다. Park et al.의 “BAM: BottleNeck Attention Module”은 최근에 많이 연구가 되는 집중(attention) 개념과 관련된 논문이다. 딥러닝 모델에게 어느 부분을 집중해서 보고 판단할지 알려주는 효과를 낼 수 있는 네트워크 모듈을 제안하는데, 좀 더 구체적으로는 이미지의 ‘무엇’을 집중해서 봐야 할 지를 정해주기 위해 채널을 다루는 부분과 ‘어디’를 집중해서 봐야 할 지를 알려주기 위해 이미지의 가로, 세로의 공간적 부분을 다루는 두 가지 부분으로 구성되어있다.
해당 모듈은 어느 CNN 구조에든 적용될 수 있는 범용성이 있으며, 분류(classification) 뿐만 아니라 위치정보까지 찾아내는 검출(detection)문제, 또 다양한 데이터셋에 대해서 실험하여 효과가 있음을 보여주어서 실용적일 수 있겠다는 생각이 들었다. 해당 논문에 대한 후속연구로 거의 비슷한 시기인 ECCV 2018에 발표된 CBAM이라는 논문도 있는데 참고해봐도 좋을 것이다.
논문 4: Innamorati et al., Learning on the Edge: Explicit Boundary Handling in CNNs
Innamorati et al.의 Learning on the Edge: Explicit Boundary Handling in CNNs”은 컨볼루션 연산에서 이미지 크기가 맞지 않을 때 사용하는 패딩(padding)과 관련된 논문이다. 패딩 방법으로 큰 고민 없이 제로 패딩이나 평균값 혹은 가장자리 부분과 똑같은 값으로 채워주는 방법들을 이용하는데, 해당 논문은 가장자리 유형별로 연산을 다르게 해서 패딩 자체도 네트워크가 배우게 하려는 의도를 담았다. 이런 패딩 방법을 세그멘테이션 기반의 다양한 작업에 사용하여 효과가 있음을 보여주었는데, 앞서 소개한 다른 연구들과 비슷하게 평소에 고민하지 않은 부분에 대해 고민했다는 점이 흥미로웠다.
논문 5: Guo et al. Network Decoupling: From Regular to Depthwise Separable Convolutions
마지막으로 Guo et al.의 “Network Decoupling: From Regular to Depthwise Separable Convolutions”는 역시 근래에 많은 유명 아키텍처에서 활용되었었던 ‘depth-wise separable convolution’에 관련된 논문이다. ‘depth-wise separable convolution’은 간단히 설명하면 아래 그림과 같이 기존의 컨볼루션과 다르게 공간(spatial)과 관련된 컨볼루션과 채널과 관련된 컨볼루션을 따로 적용하여 파라미터 수를 낮추는 컨볼루션이다.
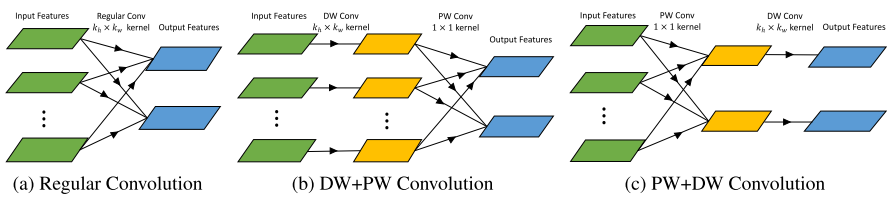 (a):일반적인 컨볼루션과 (b), (c):’depth-wise separable convolution’ 의 도식도. ‘depth-wise separable convolution’은 ‘point-wise(PW) convolution’과 ‘depth-wise(DW) convolution’ 의 순서에 따라 두 가지 종류가 있다.
(a):일반적인 컨볼루션과 (b), (c):’depth-wise separable convolution’ 의 도식도. ‘depth-wise separable convolution’은 ‘point-wise(PW) convolution’과 ‘depth-wise(DW) convolution’ 의 순서에 따라 두 가지 종류가 있다.
해당 논문은 여러 개의 ‘depth-wise separable convolution’의 합으로 기존 컨볼루션을 표현할 수 있다는 것을 수학적으로 증명하고, 이를 이용해서 기존의 컨볼루션을 ‘depth-wise convolution’ + ‘point-wise convolution’으로 분리(decoupling)하여 네트워크의 추론 속도를 높이는 방법을 제안한다.
‘depth-wise separable convolution’의 수학적인 해석도 흥미로웠고, 해당 논문에서 제시한 방법들과 중복으로 사용할 수 있는 방법들을 사용하여 최대 4배까지 추론 시간을 단축했다고 하니 딥러닝 모델의 추론 속도가 주요 문제인 경우 참고해볼 수 있겠다는 생각이 들었다. 단, 네트워크 분리 방법론은 이미 네트워크 구조에 중복이 많이 포함된 경우에 그 효과가 크다고 하니 그렇지 않은 경우에는 효과가 그리 크지 않을 수도 있다는 점을 고려해야 할 것이다.
이상 BMVC 2018의 대칭성에 관련된 키노트와 그 외 흥미 있었던 5편의 논문들에 대해서 간략히 살펴보았다. 이보다 더 큰 학회에 비해 질적으로나 양적으로 부족한 면이 있을 수 있겠지만, 오히려 적정 규모의 학회이다 보니 모든 논문을 한 번씩 관심 있게 볼 수 있을 수 있었던 것 같아 보람이 있었다. 마지막으로 BMVC 2018가 열렸던 도시 뉴캐슬어폰타인의 타인강의 멋진 다리를 보면서 글을 마치도록 하겠다.
