Transfer Learning in SUALAB: 데이터셋 제작부터 Adaptive Transfer Learning까지
본 글에서는 전이 학습(transfer learning)이라는 분야에 대해 소개해드리고, 해당 분야를 제가 재직중인 수아랩이라는 회사에서는 어떤 식으로 연구하고 있는지 직접 수행한 작업들과 간단한 실험 결과 일부를 공유드리면서, 추후 연구 방향에 대해 이야기해보려고 합니다. 본 글은 수아랩 기술 블로그에 게시하기 위해 작성된 글로, 회사에 대해 조금은 알고 계신 독자분들을 대상으로 작성된 글이라는 점을 참고해서 읽어주시면 감사하겠습니다. (간단히 말씀드리면 수아랩은 딥러닝을 이용한 머신 비전 솔루션을 제공하는 회사입니다. 쉽게 말하면 이미지를 기반으로 불량품 검사 등을 하는 회사라고 생각하셔도 좋습니다.)
서론: 수아랩의 칼 솜씨
솜씨 좋은 킬러가 수식어가 무색하게 공중목욕탕에서 미끄러지면서 머리를 다쳐 기억을 잃고 맙니다. 이와 더불어 목욕탕의 물품 보관함 키가 바뀌는 바람에 새로운 사람의 인생을 살게 된 킬러는 우여곡절 끝에 분식집에서 일하게 되는데, 뛰어난 칼 실력으로 재료 손질과 김밥 썰기를 순식간에 처리하고 단무지 꽃 등으로 손님들의 마음을 사로잡아 분식집에 사람이 몰리게 만듭니다. ‘럭키’라는 영화에 등장하는 주인공의 이야기입니다. 그가 갑자기 분식집에서 일하게 되었음에도 불구하고 빠르게 적응하고 뛰어난 성과를 이뤄낸 것은 킬러로써의 기술력(칼 솜씨)이 있었기 때문이라고 생각합니다.
 분식집에서 칼을 가는 전직 킬러(영화 '럭키')
분식집에서 칼을 가는 전직 킬러(영화 '럭키')
킬러가 아닌 수아랩의 기술력은 무엇일까요? 연구 인력, 제품(수아킷, 장비), 특허, 논문 등이 될 수도 있지만, 딥러닝을 연구하는 입장으로는 가장 큰 부분 중 하나가 내부적으로 축적된 데이터셋이라고 생각합니다. 수아랩은 데이터셋을 자체적으로 제작하기도하고 고객사로부터 연구를 의뢰받으면서 취득하기도 합니다. 그리고 이렇게 내부적으로 축적된 비전 검사 데이터셋들을 연구시 벤치마크 데이터셋으로 사용하고 있습니다.
Transfer Learning
이렇게 축적된 데이터셋들을 단순 벤치마킹 이외의 방법으로 활용할 수는 없을까요? 이러한 문제의식에서 출발하여 수아랩이 집중하고 있는 연구 분야 중 전이 학습(transfer learning)이라는 분야가 있습니다. 전이 학습은 하나의 문제를 풀기 위한 지식을 추출하여 다르지만 관련 있는 문제에 적용하는 시나리오를 연구하고 있는 분야입니다. 이때 ‘하나의 문제’를 일반적으로 소스(source)라고 표현을 하고 소스에서 가져온 지식(knowledge)을 적용하는 ‘다르지만 관련 있는 문제’를 타겟(target)이라고 지칭합니다. 영화 ‘럭키’를 예를 들면 소스인 킬러의 일에서 배운 지식인 칼 솜씨를 타겟인 분식집 일에 적용한 경우라고 볼 수 있습니다.즉 아래와 같은 그림으로 간단하게 표현될 수 있는 문제를 다루고 있는 분야입니다.
 전이 학습 도식도
전이 학습 도식도
일반적으로 전이 학습은 타겟에서의 부족한 정보를 소스로부터 보충하고자 할 때 많이 쓰입니다.(위 도식도에서 타겟의 원을 조금 작게 그린 이유도 이 때문입니다.) 이미지 분류를 예로 들면 이미지넷(ImageNet)과 같은 대용량 데이터셋을 이용해 사전학습(pre-training)한 모델을 가져와서 본 목적에 해당하는 학습(e.g. 개, 고양이 분류)시 모델을 초기화하고 파인튜닝(fine-tuning)하는 경우에 보통 ‘전이 학습’을 적용했다고 표현합니다. 이 경우 소스 데이터셋은 이미지넷, 지식은 사전학습된 모델(pre-trained model), 타겟 작업은 개, 고양이 분류 문제가 되겠습니다.
 개/고양이 분류 문제를 위한 이미지넷 전이 학습 도식도
개/고양이 분류 문제를 위한 이미지넷 전이 학습 도식도
이외에도 전이 학습은 많은 연구에서 광범위하게 쓰이는 용어인데, 지금부터는 수아랩에서 전이 학습과 관련된 어떤 연구를 했었는지 수행한 작업들과 실험 결과들을 공유드리겠습니다.
Transfer Learning in Sualab
데이터 정리 및 통합 데이터셋 제작
시작은 데이터를 정리하는 작업이였습니다. 수아랩의 주력 분야인 비전 검사라는 하나의 목표로 수집 및 제작된 데이터셋들은 저장 구조, 파일 종류, 레이블링 등이 모두 중구난방의 형태로 존재하였습니다. 따라서 효율적인 사용을 위해 통합된 형식으로의 정리가 필요하였습니다. 조금 구체적으로는 Pascal VOC Challenge에서 사용했던 데이터셋 구조 등을 참고하여 데이터 정리 규약을 만들고 정리하였습니다.
 Pascal VOC 챌린지에서 사용했던 데이터셋 구조. 레이블링 정보(Annotations, SegmentationClass, SegmentationObject), 실제 이미지(JPEGImages), 학습/검증용으로 분할된 이미지 이름 목록(Imagesets) 등이 구분되어 저장되어있습니다.
Pascal VOC 챌린지에서 사용했던 데이터셋 구조. 레이블링 정보(Annotations, SegmentationClass, SegmentationObject), 실제 이미지(JPEGImages), 학습/검증용으로 분할된 이미지 이름 목록(Imagesets) 등이 구분되어 저장되어있습니다.
그리고 정리된 단일 이미지 분류 문제(한 장의 이미지를 이용하여 클래스를 구분) 데이터셋을 통합하여 이미지넷과 같은 하나의 큰 데이터셋을 만들었습니다. 통합 데이터셋의 클래스 구성은 통합되기 이전의 어떤 데이터셋에 속해 있었는지와 해당 데이터셋의 클래스를 모두 구분하도록 구성하였습니다. 예를 들어 통합 전의 개별 데이터셋이 ‘가’와 ‘나’가 있었고, 데이터셋 ‘가’는 클래스 1, 클래스 2, ‘나’ 데이터셋은 클래스 1, 클래스 2, 클래스 3이 있었다고 하면 통합한 데이터셋은 개별 데이터셋의 종류와 클래스를 모두를 구분하는 5개의 클래스로 구성하는 식입니다.
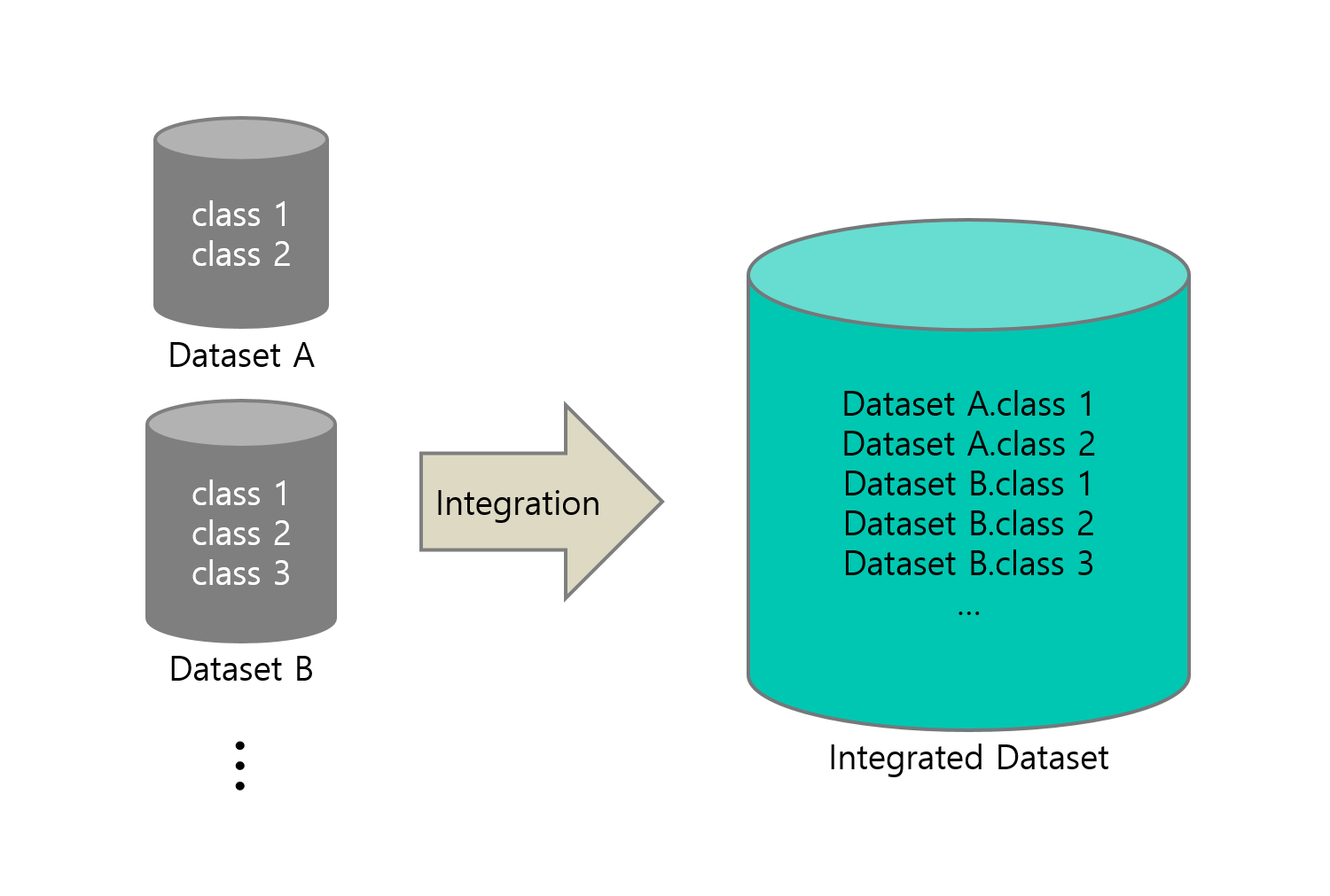 통합 데이터셋의 클래스 구성 예시
통합 데이터셋의 클래스 구성 예시
데이터셋 전처리
해당 데이터셋을 만들 때 2가지의 문제점이 있었습니다. 첫 번째는 이미지 크기 다양성의 문제입니다. 예를 들면 이미지 크기가 가로x세로 100x100인 이미지부터 2000x2000인 이미지까지 다양한 이미지가 존재하였습니다. 보통 딥러닝 모델의 입력값으로 크기가 동일한 이미지를 받는 경우가 많으므로, 크기가 통일되면 좀 더 편리하게 데이터셋을 사용할 수 있습니다. 이를 해결하기 위해서 일부 데이터셋에 대해 리사이징 및 제로 패딩을 하였고, 지나치게 크고 결함의 크기가 작은 데이터셋 같은 경우에는 결함 정보가 리사이징으로 사라질 수 있기 때문에 패치 크로핑을 이용해서 모든 이미지들을 가로와 세로를 모두 최소 224, 최대 256 사이로 맞추었습니다.
 전처리 전/후의 이미지 크기(픽셀 수의 제곱근) 분포 예시
전처리 전/후의 이미지 크기(픽셀 수의 제곱근) 분포 예시
두 번째는 클래스 불균형 문제입니다. 통합된 데이터셋은 적게는 10장 이하의 이미지를 포함하는 클래스부터 많게는 10만 장을 넘어가는 이미지를 포함하고 있는 클래스도 존재하였습니다. 클래스가 이처럼 불균형하게 분포하게 되면 소수에 해당하는 클래스는 학습이 되지 않거나, 학습이 불안정하게 진행되는 경우가 있으므로 이를 완화하는 것이 좋습니다. 해당 문제를 해결하기 위해서 클래스당 이미지 수의 기준값을 정해두고 기준값을 넘는 클래스에 대해서는 기준값만큼의 이미지만 랜덤으로 추출해서 사용하고 나머지는 사용하지 않는 방식의 언더 샘플링(under-sampling)을 수행하였습니다.
 언더샘플링 전/후의 클래스별 이미지 수 분포 예시
언더샘플링 전/후의 클래스별 이미지 수 분포 예시
통합 데이터셋: SRISC(Sualab Research Image Single Classification)
이제 이미지 크기의 다양성이 적고, 클래스가 어느 정도 균형이 잡힌 데이터셋이 생겼습니다. 이를 SRISC(Sualab Research Images Single Classification)라고 지칭하였습니다. 추후 계속 발전되었지만 초기 SRISC는 PCB, 필름, 디스플레이, 태양광, 반도체 등 다양한 산업군의 데이터를 포함하고 있는 대용량 데이터셋이었습니다. 특징으로는 산업용 이미지다 보니 자연계 이미지인 이미지넷에 비해 1 채널 이미지들이 많이 있다는 점이 있었습니다.
SRISC를 이용한 사전학습
이미지넷을 이용해서 사전학습을 하듯이 완성된 SRISC를 이용해서 사전학습하는 방식을 통해 본격적으로 전이 학습에 활용하였습니다. 기본적으로 소스 데이터셋에서의 각 클래스들을 구분하도록 사전학습한 뒤 새로운 (타겟) 데이터셋 학습 시 모델의 초기값으로 해당 사전학습된 모델을 사용하였습니다. 그리고 사전학습 시 사용하는 소스 데이터셋의 종류와 사전학습 방법에 따른 전이 효과를 알아보기 위해 아래와 같이 5가지 사전학습 방법에 따라 타겟 작업에서의 성능이 어떻게 변화하는지 비교하였습니다.
- 사전학습 하지 않음(from_scratch)
- 이미지넷 사전학습(ImageNet_pre-trained)
- SRISC 사전학습(SRISC_pre-trained)
- 이미지넷 1차 사전학습 후에 SRISC 2차 사전학습(ImageNet_SRISC_pre-trained)
- 데이터를 통합하여 이미지넷과 SRISC을 동시에 사전학습(ImageNet-SRISC_joint-pre-trained)
사전학습 이후 사전학습한 모델을 이용하여 SRISC에 포함되지 않았던 4개의 새로운 비전 검사 데이터셋에 대한 학습 및 테스트를 하였고, 그 결과는 아래와 같습니다. 타겟 데이터셋의 산업군은 전자부품(electronic component), 음료(beverage), 필름(film), 디스플레이(display)로 다양하게 구성하였습니다. 여러 번 반복 실험한 뒤 테스트 셋에 대한 오류율(error rate)의 평균을 각 사전학습 방법 별로 나타내었습니다.
 사전학습 방법에 따른 전이 성능(타겟 테스트셋에 대한 오류율)
사전학습 방법에 따른 전이 성능(타겟 테스트셋에 대한 오류율)
결과는 각 타겟 데이터셋 별로 어느정도 차이가 있었지만 이미지넷과 SRISC를 함께 이용할 경우 이미지넷만을 이용한 경우보다 모든 데이터셋에서 오류율이 줄어드는 결과(그래프에서 붉은색 막대)를 보여주었습니다. 또한 SRISC만 이용하는 경우 성능이 이미지넷으로만 사전학습한 경우보다 좋은 경우(전자부품, 음료)도 있었고, 방법적인 측면에서는 이미지넷과 SRISC를 동시에 사전학습하는 것보다는 순차적으로 사전학습하는 방법이 좋은 결과를 보였습니다.
이러한 결과는 비전 검사를 위한 데이터셋을 학습할 때는, 같은 비전 검사라는 공통점을 가진 데이터셋을 이용하여 전이 학습하면 성능을 향상할 수 있음을 보여주는 결과입니다. 여기서 한발 더 나아가 비전 검사 내 세부 영역으로 더 범위를 좁힌다면 성능이 올라가지 않을까요?
SRISCPCB를 이용한 사전학습
그리하여 SRISC에서 많은 비중을 차지하고 있던 PCB 산업군의 데이터셋만을 모아서 선별적으로 전이 시 성능이 더 많이 올라가는지 확인해보고자 PCB 산업군에 속하는 데이터셋을 모아서 SRISCPCB를 만들었습니다. SRISCPCB를 만들 때는 클래스 개수가 상대적으로 적었으므로, 클래스 불균형 해결보다 절대적인 데이터의 양을 늘리는데 초점을 맞추기 위해 사용할 수 있는 모든 데이터셋을 사용하였습니다. 그리고 앞 선 실험의 결과를 참고하여 아래 3가지 방법으로 사전학습한 뒤, 각 사전학습된 모델을 초기값으로 5개의 사전학습에 사용되지 않은 타겟 PCB 데이터셋에 대해 학습하여 성능을 측정하였습니다.
- 이미지넷으로 사전학습(대조군, ImageNet_pre-trained)
- 이미지넷, SRISC순으로 사전학습(대조군, ImageNet_SRISC_pre-trained)
- 이미지넷, SRISC, SRISCPCB 순으로 사전학습(실험군, ImageNet_SRISC_SRSICPCB_pre-trained)
역시 타겟 테스트 데이터셋에 대한 오류율로 성능을 표시하였습니다.
 PCB 도메인 대상 사전학습 방법에 따른 전이 성능(타겟 테스트셋에 대한 오류율)
PCB 도메인 대상 사전학습 방법에 따른 전이 성능(타겟 테스트셋에 대한 오류율)
모든 타겟 PCB 데이터셋에서 SRISCPCB를 이용하여 추가적으로 사전학습하는 경우 성능이 좋아지는 경향을 보였습니다. 소스 데이터셋을 더욱 선별적으로 사용한 효과를 본 것입니다.
도메인 좁히기의 한계
그런데 한발 더 나아가서 PCB를 다시한번 하위 도메인으로 나눠 실험하였을 때는 성능의 향상이 없는 결과를 보였습니다. 아마 너무 도메인을 세분화한 나머지 소스 데이터셋 내 전이할 지식의 양이 줄어들었기 때문일 것입니다. 그렇다면 소스 데이터셋을 많이 사용하면 성능이 많이 향상시킬 수 있을 것이라는 생각에 SRISC의 크기를 증가시켜가면서 사전학습 및 파인튜닝 과정의 성능을 측정해본 결과, 성능이 향상되다가 특정 지점 이후 줄어드는 경향을 보였습니다. 원인으로 데이터가 많아지면서 전이에 부정적인 영향을 미치는 데이터셋이 포함되었을 가능성을 생각해볼 수 있습니다. 이렇게 소스 데이터셋들을 사람의 주관대로 선택하면서 실험을 하다보니, 결론적으로는 전이 시 성능이 좋아질지 아니면 오히려 나빠질지 확신하기 어렵겠다는 생각이 들었습니다. 좀 더 객관적인 방법으로 소스 데이터셋을 선택하는 방법이 없을까요?
Adaptive Transfer Learning
이미 위와 같은 문제의식을 공유하는 연구들이 있습니다. 이러한 연구들은 소스를 선택하는 기준이나 방식을 연구하는데, 저는 이러한 연구분야를 적응적 전이 학습(Adaptive Tansfer Learning)이라고 지칭하겠습니다. 몇 가지 예시 연구를 열거해보면 아래와 같습니다.
- Garbor filter를 이용하는 등 저수준(low-level)의 피쳐를 이용하여 이미지 간 유사도를 계산해 타겟과 유사한 소스 이미지들을 선택하여 이용하는 방법론 (Ge and Yu, 2017)
- 미리 학습된 딥러닝 모델의 피쳐를 이용해서 계산한 클래스 간 유사도를 이용하는 방법론 (Cui et al., 2018)
- 소스 선택 자체를 데이터를 기반으로 학습하는 방법론 (Litany and Freedman, 2018)
본 글에서는 여러 방법론들 중에서 가장 간단한 방식이라고 할 수 있는 아래와 같은 방법론(Ngiam et al., 2018)을 기반으로 실험을 진행해보았습니다.
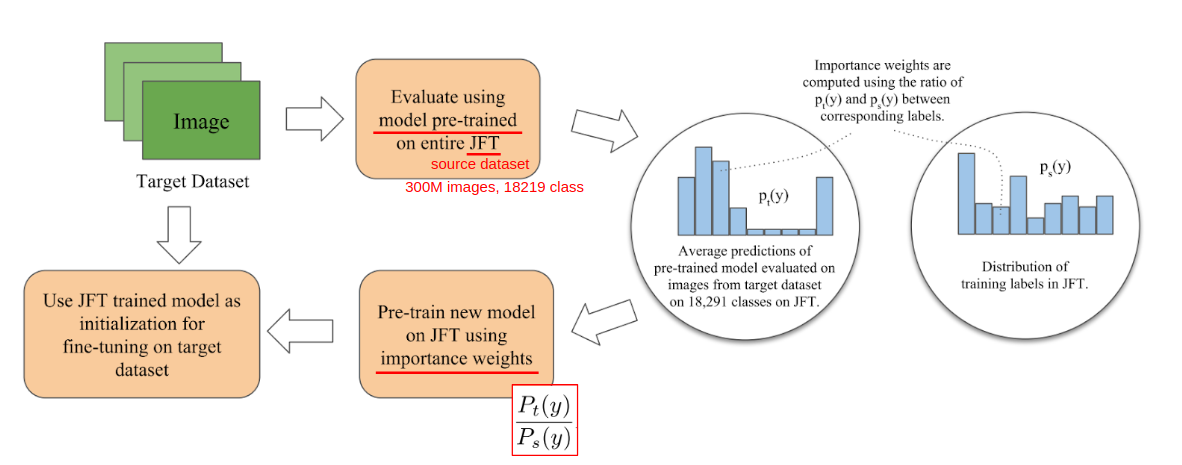 Ngiam et al.(2018)의 Adaptive Transfer Learning 방법론
Ngiam et al.(2018)의 Adaptive Transfer Learning 방법론
해당 방법론은 아래와 같은 4단계로 이루어져 있습니다.
- 미리 소스 데이터셋을 이용해서 학습해놓은 모델을 이용해서 타겟 데이터셋에 대해서 추론(inference)
- 이전 단계에서 얻은 결과에서 확률이 높게 나온 클래스가 높은 가중치를 가지도록 소스 클래스별 가중치(importance weight) 산출
- 이전 단계에서 얻은 가중치를 기반으로 배치 샘플링하여 다시 한번 사전학습
- 이전 단계에서 사전학습한 모델을 최종 타겟 학습의 초기값으로 사용
SRISC를 이용한 전이 학습 시나리오를 예를 들면 타겟이 PCB 산업군의 데이터셋이었다면 초기 추론과정에서 타겟과 유사한 소스 데이터의 다른 PCB 데이터셋 클래스로 추론이 될 것이고, 이렇게 추론된 PCB 클래스들을 위주로 사전학습을 하겠다는 의도입니다.
실험은 기본적으로 이미지넷 사전학습은 공통으로 수행하고 이후 아래 3가지 방법으로 사전학습을 달리해가면서 성능을 측정하였습니다.
- 전체 SRISC의 클래스를 균일하게 사전학습(ImageNet_SIRSC_pre-trained)
- 위 방법론을 이용해서 SRISC에 대해 사전학습(ImageNet_Adaptive-SRISC_pre-trained)의
- 글쓴이 개인적인 직관에 따라 임의로 선택한 클래스들을 이용해서 사전학습(ImageNet_Human-curated-SRISC_pre-trained)
단, 세번째 항목의 경우, 일부 산업군의 데이터셋은 어떤 클래스들을 골라야 할지 감이 잡히지 않아 고르지 못한 데이터셋도 있습니다. 이렇게 사람 기준에서 애매한 데이터셋들에 대해서도 적용될 수 있다는 점은 여기서 시도해본 방법론을 포함하여 적응적 전이 학습 방법론들의 강점입니다.
성능은 역시 타겟 테스트 셋의 오류율로 표기하였습니다.
 Adaptive Transfer Learning의 방법론을 적용하여 사전학습한 경우의 전이 성능
Adaptive Transfer Learning의 방법론을 적용하여 사전학습한 경우의 전이 성능
아쉽게도, 전반적으로 긍정적인 결과는 아니였습니다. SRISC를 단순하게 이용해서 사전학습한 경우보다 오류율이 줄어드는 경우도 있었지만, 높아지는 경우도 있었습니다. SRISC가 아직 데이터를 선택적으로 이용할 만큼 충분한 크기의 소스 데이터셋이 아니였거나, 선정기준이었던 타겟과 유사한 소스 데이터셋이 실제 사전학습을 통해 타겟에서 성능을 올려주는 데이터셋은 아니었을 수 있습니다. 추가적으로 사람의 기준으로 데이터셋을 고를 경우에도 성능이 좋아지는 경우가 있었지만 나빠지는 경우도 있었는데, 이는 사람의 주관이 부정적인 영향을 미친 사례라고 볼 수 있습니다. 아직 적응적 전이 학습, 특히 소스 데이터셋 선정 기준에 대해서는 좀 더 고민해볼 여지가 있는 것 같습니다.
사전학습 방식의 Transfer Learning의 한계
앞서 보여드린 실험 결과들에서도 나타나지만 지금까지 보여드린 방식의 전이 학습은 아직 많은 한계점을 가지고 있습니다. 가장 대표적이고 쉽게 생각할 수 있는 것은 이미 타겟 데이터셋이 많은 양을 보유한 경우에는 그 효용이 그렇게 크지 않다는 점입니다. 이를 보여주는 그래프는 아래와 같습니다.
 타겟 데이터셋 크기에 따른 전이 학습 적용 후 정확도 이득
타겟 데이터셋 크기에 따른 전이 학습 적용 후 정확도 이득
타겟 학습 데이터셋 크기에 따른 SRISC를 이용한 전이 학습 적용 후 정확도 이득(Accuracy Gain, 적용 전에 비해 정확도가 얼마나 증가했느냐)을 나타낸 그래프입니다. 확실히 타겟 데이터셋이 커질수록 전이 학습 방법 차이에 따른 효용은 작아지는 양상을 보입니다. 현재 방식의 전이 학습은 초기값의 차이만을 만들어내는데, 많은 타겟 데이터셋을 학습하는 과정에서 그 차이의 효과가 희석되기 때문입니다.
Transfer Learning 추후 연구 방향
앞서 언급한 한계점을 극복하거나 더 높은 성능 향상을 위해 앞으로 전이 학습 연구를 발전시킬 수 있는 방향은 구체적으로 크게 3가지로 나눌 수 있는데, 글 초입부에서 보여준 그림을 기준으로 각 단계를 나누어서 볼 수 있습니다.
 전이 학습 추후 연구 방향 도식도
전이 학습 추후 연구 방향 도식도
(1) 첫 번째로는 소스를 선택하는 과정을 지금보다 더 현명하게 할 수 있는 방법을 고안해 볼 수 있습니다. 어떤 소스 데이터셋이 얼마나 타겟에서 효과가 있느냐를 전이성(transferability)이라고 할 때, 전이성의 대변자(proxy)로써 앞서 살펴본 방법론은 미리 소스 데이터셋으로 학습된 모델의 결과를 이용했는데 다른 방법으로 전이성을 측정하여 선택할 수 있을 것입니다. 적응적 전이 학습(Adaptive Transfer Learning) 연구들이 해당 계열에 속한 연구의 대표적인 예시라고 할 수 있습니다.
(2) 두 번째는 전이되는 지식이 무엇이냐, 어떻게 전이시키느냐를 달리 해볼 수 있을 것 같습니다. 지금까지 소개된 연구들은 학습된 모델을 지식으로 보고, 사전학습 및 파인튜닝 방식을 이용한 모델 전이 방식이었습니다. 하지만 이 방법 이외의 소스 데이터셋 자체를 지식으로 보고 데이터 자체를 전이하여 조인트 트레이닝(joint-training) 혹은 다중 작업 학습(multi-task learning) 방식으로 타겟 도메인에서 학습하거나, 웨이트가 아닌 아키텍쳐만 옮겨오는 아키텍처 전이 등 다양한 방법이 있을 것 같습니다.
(3) 마지막으로 전이해온 지식을 타겟에 적용할 때도 다양한 방법을 시도해볼 수 있습니다. 현재까지는 대부분 모든 레이어를 동일한 학습률(learning rate)로 학습하는 방식을 이용하였지만, 일부 레이어를 프리즈 시키거나, 혹은 전이해온 웨이트가 학습을 하면서 초기값에서 크게 변하지 않게 정규화를 해주는 식의 시도도 해볼 수 있다고 생각합니다. (Li et al., 2018)와 (Li et al., 2019)와 같은 연구를 참고할 수 있습니다.
좀 더 나아가면 이렇게 3가지 이외에 작업 자체를 분류 말고 세그멘테이션, 디텍션 등 이종 작업 간의 전이를 시도해볼 수도 있고, 전이 학습 자체가 포괄적인 의미를 담고 있는 분야라 전이 학습의 하위 이름으로 시도해볼 수 있는 다양한 연구들이 존재합니다.
마무리
여기까지 전이 학습의 개념과 수아랩에서 전이 학습을 연구했던 내용을 간략히 공유해드리고, 앞으로 나아가야 할 연구 방향에 대해서도 이야기해보았습니다. 앞으로도 수아랩의 가장 큰 칼솜씨(기술력) 중 하나인 데이터셋을 이용하기 위한 전이 학습은 계속해서 연구가 될 예정이니 많은 관심 부탁드립니다.
References
- Ge and Yu. “Borrowing treasures from the wealthy: Deep transfer learning through selective joint fine-tuning.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- Cui et al. “Large scale fine-grained categorization and domain-specific transfer learning.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Litany and Freedman. “SOSELETO: A Unified Approach to Transfer Learning and Training with Noisy Labels.” arXiv preprint arXiv:1805.09622 (2018).
- Ngiam et al. “Domain adaptive transfer learning with specialist models.” arXiv preprint arXiv:1811.07056 (2018)
- Li et al. “Explicit Inductive Bias for Transfer Learning with Convolutional Networks” ICML. 2018.
- Li et al. “DELTA: DEep Learning Transfer using Feature Map with Attention for Convolutional Networks” ICLR. 2019.
- 분식집에서 칼을 가는 전직 킬러
- 이미지넷(ImageNet) 웹사이트
- 개 고양이 분류 문제
- Pascal VOC Challenge 웹사이트
- 언더샘플링(undersampling)